Monsters Programming - Node graph system (part 1) Last edited 1 month ago2024-10-22 17:36:47 UTC
Half-Life Programming
- Monsters Programming - The Concepts of Half-Life's AI
- Monsters Programming - Schedules and Tasks
- Monsters Programming - Classifications and Relationships
- Monsters Programming - Standard and Squad Monsters
- Monsters Programming - Talkative Monsters (part 1)
- Monsters Programming - Talkative Monsters (part 2)
- Monsters Programming - "Core loop", senses and enemy acquisition
- Monsters Programming - Sounds, smells and the system behind them
- Monsters Programming - Node graph system (part 1)
Before we dive into the code that instruct monsters to move, fly and swim around, we need to talk about another major system in Half-Life's AI: the node graph.
Like the first page of this chapter, important terminology will be bold.
The next step is a call to
From this point, we will assume there is already a node graph generated and the engine/filesystem managed to read the file. This is where it gets interesting because it start by reading a graph version as an
The primary reason for the existence of this graph version is because the node graph system received a lot of changes during the development of Half-Life and thus node graphs made with an older
To prevent such issues, Valve used this graph version to detect those problematic graphs and have them rebuilt with the new data structure in mind. If you modify the system and your modification(s) involves a requirement of rebuilding all node graphs for all maps, a good habit to have is to increase the version in the
In the end, if the versions between the file and the constant are different,
Assuming the graph version is correct, data with the size of
After this, a memory allocation (
When reading the file,
Assuming the node graph has not been read because the file is missing or there was a failure during the reading process, a call to
To understand the next part of the startup process, we need to look at the structure of nodes and how the info_node entity and it's "friend" info_node_air works.
To answer that question, a node is a point, a spot or a "vertex" if you prefer to call it this way in a level. This implies that they have an origin, but a node is more than just a "specific location in the level" because it needs to hold some extra information. Let's take a look at the
Let's talk about both info_node and info_node_air entities, they're linked to the
What's more interesting is the spawning logic, after setting them to non-solid and non-moveable, there is a check if the node graph is already loaded (
Otherwise, this means the node graph has not been (re)generated yet. If this is the first node entity to be spawned (
The next part is very interesting, we can determine that
Let's talk about node type (
Now that the list of nodes is populated, we need to look at that test hull entity we mentioned earlier to understand the next part of the process. The test hull entity is an extremely basic "invisible human sized monster that uses the player model with no AI". In it's spawn logic, there is a "sanity check" to see if we should generate the node graph or not (
Otherwise, after a second has passed, it teleports itself to the first node entity then calls it's
Now we're starting to get inside the interesting parts,
The purpose of the
If
Both node's
Before we can continue in the node graph generation process, we need to talk about links.
The next method that is called is
This method also have specifics when tracing those lines and checking them:
Assuming both traces agrees that they hit the same entity, then the pointer to said entity is kept in
The method also logs those initial links in the report. You might be wondering: "what's the purpose of the
Since the result from doing those initial links is
Assuming we have no "bad nodes", we can go back to the initial
This is where the link's
After all links have passed that test, a method called
To explain this better: picture a triangle (a 2D triangle to be exact, not to be confused with a 3D pyramid) where each vertex is a node and has a name: A (bottom left), B (top) and C (bottom right). Each line connecting A-B, B-C and A-C is a link. If you need a drawing to help you, here's one: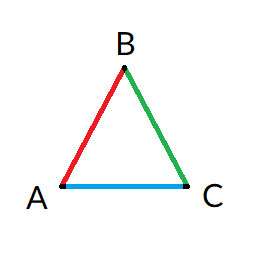 In this case, everything is nice and good. Now let's move B (top vertex) very close to the same level as A and C (bottom vertices) like this:
In this case, everything is nice and good. Now let's move B (top vertex) very close to the same level as A and C (bottom vertices) like this:
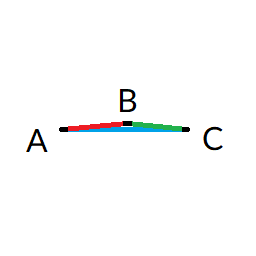 The link A-C (blue on the drawing) becomes problematic since it "overlap" with A-B (red) and B-C (green). The method checks the distances and dot products of directions to detect and remove these "overlaps". Link A-C gets removed to keep A-B and B-C.
The link A-C (blue on the drawing) becomes problematic since it "overlap" with A-B (red) and B-C (green). The method checks the distances and dot products of directions to detect and remove these "overlaps". Link A-C gets removed to keep A-B and B-C.
Let's go back to the code, the method finishes by returning the amount of links it rejected. Worth mentioning that those rejected links are logged in the report file. Another thing worth mentioning about this method: it sets the link's weight (
Before proceeding further, remember that we used a temporary list of links. Furthermore,
Instead of using an existing map from Half-Life's campaign, we're going to use a community map called "Bridge The Gap 2.0" made by Urby (used with permission) which you can download and play after reading this page if you haven't already from the TWHL Vault. After installing the map, starting it and letting the node graph process generation complete with the "recording" of steps. We can finally look at the whole stuff. First, let's see how the "initial links" in two places of the maps are created. As a remainder, those "initial links" are created by tracing lines between two nodes and checking if they're not blocked.

 During this recap, remember that "initial links" are red. The next step is the test hull trying to walk these links from small to huge size. If the small size fails, the link is rejected. Otherwise the link is kept and notes which sizes passes and those who don't. The code in the SDK calls this "walk rejection".
During this recap, remember that "initial links" are red. The next step is the test hull trying to walk these links from small to huge size. If the small size fails, the link is rejected. Otherwise the link is kept and notes which sizes passes and those who don't. The code in the SDK calls this "walk rejection".

 For this recap, the "links" that have been kept will be blue. If we want to know which links did not "survived" this step, we can render both steps like this:
For this recap, the "links" that have been kept will be blue. If we want to know which links did not "survived" this step, we can render both steps like this:

 Red and blue added together gives pink. These are the links that have been kept so far, the ones still in red were "walk rejected". Last step is the "inline rejection" one which eliminate "overlaps". Let's see which ones passes the algorithm:
Red and blue added together gives pink. These are the links that have been kept so far, the ones still in red were "walk rejected". Last step is the "inline rejection" one which eliminate "overlaps". Let's see which ones passes the algorithm:

 The links who passed this step are shown in green. Again, if we want to see which ones didn't passed this step, we can render this step and the previous one:
The links who passed this step are shown in green. Again, if we want to see which ones didn't passed this step, we can render this step and the previous one:

 Cyan is the result of combining blue and green together. You probably guessed it: the links still in blue are the ones who were "inline rejected". To finalize this recap, let's display all the steps together:
Cyan is the result of combining blue and green together. You probably guessed it: the links still in blue are the ones who were "inline rejected". To finalize this recap, let's display all the steps together:

 The "final" result is all those white links (the combination of red, green and blue together).
The "final" result is all those white links (the combination of red, green and blue together).
Monsters could request information from the node graph at any time, could be the location of a node with a specific constraint (usually the one closest to the monster itself or target or cover), could be a path from two nodes with constraints (shortest one, avoid obstacles...) and so on.
With a low amount of nodes, links and simple map geometry complexity, this would maybe not be a big deal. However, the reversed situation could happen. You need to keep in mind that Half-Life was released back in 1998. In that time period, we didn't had those fancy 64 bits, multi-cores, GHz clock speeds of processors from 2024, we only had a few 16 bits, single core and a few hundred of MHz clock speed (a Pentium 2 was 333 MHz back then). The same holds true for the memory (RAM) where we only had 16/32 Mb SDRAM and not those 16/32 Gb DDR4/DDR5 of today.
Short version: back in 1998, optimization was not an optional thing, it was a mandatory requirement. So Valve had to use many tricks to optimize the code and make sure the game would run smoothly on the hardware of that period.
Because there is a lot to talk about those optimization techniques, this will be discussed in a future page. For now, we're going to skip looking inside
We're also going to skip that next
And we're skipping the call to the
Don't worry about
Speaking of reading, there is one more thing that happens when the node graph is being loaded. When the player is being precached (
The startup
It all begins when the world also known as "worldspawn" is being precached (CWorld::Precache). There is a global variable called WorldGraph which is a CGraph class instance and it's InitGraph() method is called. In said method, several variables are reset to default values, one of them you need to know right now is bool m_fGraphPresent which can be translated to "is the node graph present and loaded", the other variables will be covered later.The next step is a call to
bool WorldGraph.FLoadGraph(char* szMapName). This method as you might have already guessed, is responsible for loading and reading the maps/graphs/<mapname>.nod file, but wait, there's more. After building the path to the mentioned file, the next thing it does is telling the engine/filesystem to load it. If it fails because said file is missing or there is a permission problem or whatever, then false is returned.From this point, we will assume there is already a node graph generated and the engine/filesystem managed to read the file. This is where it gets interesting because it start by reading a graph version as an
int and check if said version is different from the constant #define GRAPH_VERSION (int)16.The primary reason for the existence of this graph version is because the node graph system received a lot of changes during the development of Half-Life and thus node graphs made with an older
CGraph class data structure were a source of problems (incomplete data, data mismatch and even worse: crashes).To prevent such issues, Valve used this graph version to detect those problematic graphs and have them rebuilt with the new data structure in mind. If you modify the system and your modification(s) involves a requirement of rebuilding all node graphs for all maps, a good habit to have is to increase the version in the
#define GRAPH_VERSION constant to invalidate those now obsolete node graphs and force them to be rebuilt. If you are a web developer, it's kinda the same habit of increasing an API version when major changes are made and consumers are required to make changes to use the new version.In the end, if the versions between the file and the constant are different,
false is returned.Assuming the graph version is correct, data with the size of
sizeof(CGraph) is read from the file for some variables we'll see later, then some interesting pointers are reset to NULL just in case we would run out of memory. Back in 1998/1999, we had systems with 16/32 Mb of RAM, not those fancy 16/32/64 Gb in 2024.After this, a memory allocation (
calloc) is performed for the nodes (m_pNodes) using sizeof(CNode) as the size and m_cNodes as the count. After that allocation, sizeof(CNode) * m_cNodes are read. Then we repeat the process with links (m_pLinkPool/CLink/m_cLinks), sorting info (m_di/DIST_INFO/m_cNodes), routing info (m_pRouteInfo/char/m_nRouteInfo) and hash links (m_pHashLinks/short/m_nHashLinks). Don't worry all of these terms will be explained later when the time comes.When reading the file,
false is returned if a memory allocation operation fails or it is expected to read more data and there is nothing else to read ("corrupted file/loss of data" syndrome). true is returned when the node graph has been read successfully.Assuming the node graph has not been read because the file is missing or there was a failure during the reading process, a call to
CGraph::AllocNodes() is made which makes a memory allocation for the nodes like explained above. The difference this time is that we're using the constant #define MAX_NODES 1024 as count instead of m_cNodes that we would read from the saved node graph. This will be used later during the generation process.To understand the next part of the startup process, we need to look at the structure of nodes and how the info_node entity and it's "friend" info_node_air works.
Nodes and the "test hull"
In the previous section, the word node was used a lot and you might be wondering at this point: "what the hell is a node in the first place?".To answer that question, a node is a point, a spot or a "vertex" if you prefer to call it this way in a level. This implies that they have an origin, but a node is more than just a "specific location in the level" because it needs to hold some extra information. Let's take a look at the
CNode class which is how a single node is "modeled" in the code:
class CNode
{
public:
Vector m_vecOrigin; // location of this node in space
Vector m_vecOriginPeek; // location of this node (LAND nodes are NODE_HEIGHT higher).
byte m_Region[3]; // Which of 256 regions do each of the coordinate belong?
int m_afNodeInfo; // bits that tell us more about this location
int m_cNumLinks; // how many links this node has
int m_iFirstLink; // index of this node's first link in the link pool.
// Where to start looking in the compressed routing table (offset into m_pRouteInfo).
// (4 hull sizes -- smallest to largest + fly/swim), and secondly, door capability.
int m_pNextBestNode[MAX_NODE_HULLS][2];
// Used in finding the shortest path. m_fClosestSoFar is -1 if not visited.
// Then it is the distance to the source. If another path uses this node
// and has a closer distance, then m_iPreviousNode is also updated.
float m_flClosestSoFar; // Used in finding the shortest path.
int m_iPreviousNode;
short m_sHintType; // there is something interesting in the world at this node's position
short m_sHintActivity; // there is something interesting in the world at this node's position
float m_flHintYaw; // monster on this node should face this yaw to face the hint.
};Vector that represent the origin, the node info (int m_afNodeInfo) and the last three variables about hints.Let's talk about both info_node and info_node_air entities, they're linked to the
CNodeEnt class, not solid and cannot move. Level designers can configure a "hint type" and "activity hint" but as already mentioned in one the previous pages: Valve didn't had time to finish the "hint" system and thus those are left unused. They did finished and revamped it in Half-Life 2 tho.What's more interesting is the spawning logic, after setting them to non-solid and non-moveable, there is a check if the node graph is already loaded (
bool WorldGraph.m_fGraphPresent == true), if that's the case, the entity is removed right away.Otherwise, this means the node graph has not been (re)generated yet. If this is the first node entity to be spawned (
WorldGraph::m_cNodes == 0), then it spawn a test_hull entity (linked to the CTestHull class) passing itself as parameter in its Spawn method. The test hull entity will make sense in a few. Another check is made to see if we are exceeding the maximum amount of nodes (WorldGraph.m_cNodes >= MAX_NODES), if that's true, the node entity is removed right now.The next part is very interesting, we can determine that
CNode* WorldGraph.m_pNodes is a "list of nodes" and m_cNodes in this context act as an "index" because it gets incremented after setting some information about said node. The information being set is the node's origin, the (unused) hints and if the entity is an info_node_air, the bits_NODE_AIR node type is set.Let's talk about node type (
int CNode::m_afNodeInfo) for a second, it allow to make the distinction between land, air and water nodes because it can have the following bits set:
#define bits_NODE_LAND (1 << 0) // Land node, so nudge if necessary.
#define bits_NODE_AIR (1 << 1) // Air node, don't nudge.
#define bits_NODE_WATER (1 << 2) // Water node, don't nudge.
#define bits_NODE_GROUP_REALM (bits_NODE_LAND | bits_NODE_AIR | bits_NODE_WATER)bits_NODE_GROUP_REALM to group them all. After incrementing the index, the entity is removed.Now that the list of nodes is populated, we need to look at that test hull entity we mentioned earlier to understand the next part of the process. The test hull entity is an extremely basic "invisible human sized monster that uses the player model with no AI". In it's spawn logic, there is a "sanity check" to see if we should generate the node graph or not (
bool WorldGraph.m_fGraphPresent == false). If that check fails, the entity is removed immediately.Otherwise, after a second has passed, it teleports itself to the first node entity then calls it's
CallBuildNodeGraph() method. The purpose of said method is simple: disable everything that could call the Touch method in entities (see the bool gTouchEnabled global variable and DispatchTouch(edict_t* pentTouched, edict_t* pentOther) function in dlls/cbase.cpp), actually call the BuildNodeGraph() method and re-enable those "touches" after the generation process is over.Now we're starting to get inside the interesting parts,
BuildNodeGraph() make the test hull remove itself on the next "simulation/thinking" frame, but before that frame happens, the node graph generation process continues. It initialize a temporary list of links, and create the maps/graphs/<mapname>.nrp file. Yes, you've read it right, the .nrp file and not the .nod file, that's not an error.The purpose of the
.nrp file is simple: it's a text file that you can open with your favorite text editor and it act as a "report" (or "log" if you prefer to call it this way) of the node graph generation process. At the beginning of the file and node graph generation process, all the information about nodes gathered earlier are logged first.
After that logging part, we "restart" a loop on these nodes and three situations can happen:
- If the node is in the air (set previously by info_node_air), then nothing "fancy" happens.
- If the node is underwater (
UTIL_PointContents( Vector vecSrc ) == CONTENTS_WATER), then thebits_NODE_WATERflag is added to the node'sm_afNodeInfo. - Otherwise, the node is considered to be "land on the ground", the
bits_NODE_LANDflag is added to the node'sm_afNodeInfo.
ignore_monsters and the other one uses dont_ignore_monsters when it comes to ignoring entities, they are stored in tr and trEnt respectively.If
trEnt hit something closer than tr, hits an entity and said entity is a world brush (entity's v.flags has the FL_WORLDBRUSH flag set), then the value of tr.vecEndPos is changed to be the same as trEnt.vecEndPos. To rephrase this: the purpose of those traces is to check those nodes would be stuck inside solid brush entities or not (func_door, func_wall and so on)Both node's
m_vecOrigin and m_vecOriginPeek are then moved to the end of the trace (tr.vecEndPos). In order to compensate for stairs, chairs and any other kind of small "step" (as in "watch your step"), they're lifted 8 units from the ground (defined by the constant #define NODE_HEIGHT).Before we can continue in the node graph generation process, we need to talk about links.
Links
A link is a connection between two nodes which is represented by theCLink class:
class CLink
{
public:
int m_iSrcNode; // the node that 'owns' this link (keeps us from having to make reverse lookups)
int m_iDestNode; // the node on the other end of the link.
entvars_t *m_pLinkEnt; // the entity that blocks this connection (doors, etc)
// m_szLinkEntModelname is not necessarily NULL terminated (so we can store it in a more alignment-friendly 4 bytes)
char m_szLinkEntModelname[4]; // the unique name of the brush model that blocks the connection (this is kept for save/restore)
int m_afLinkInfo; // information about this link
float m_flWeight; // length of the link line segment
};The next method that is called is
bool WorldGraph.LinkVisibleNodes(CLink* pLinkPool, FILE* file, int* piBadNode). For each node, it traces a line between that node and all others. If nothing blocks said line, the link is kept by referencing the source and destination in the proper variables, otherwise it's not kept. But wait, there's more.This method also have specifics when tracing those lines and checking them:
- A node cannot be linked to itself (doh!).
- The two nodes must be of the same type, air nodes can only be linked to other air nodes, ground nodes can only be linked to other ground nodes, water nodes can only be linked to other water nodes. A ground node cannot be linked to an air or water node, etc...
- A node cannot have 128 (
#define MAX_NODE_INITIAL_LINKS) and more links by itself. - The amount of total links cannot exceed 128 (
#define MAX_MODEL_INITIAL_LINKS) multiplied by the amount of nodes in the map (m_cNodes).
Assuming both traces agrees that they hit the same entity, then the pointer to said entity is kept in
m_pLinkEnt, the model name is kept in m_szLinkEntModelname and the entity receive the FL_GRAPHED flag which is used in the case where it's deleted (func_breakable blocking passage until it's broken for example).The method also logs those initial links in the report. You might be wondering: "what's the purpose of the
iBadNode parameter? What is a 'bad' node?" To answer these questions, let's pretend the level designer break the "nodes cannot have 128 (#define MAX_NODE_INITIAL_LINKS) and more links by itself" and/or "the amount of total links cannot exceed 128 (#define MAX_MODEL_INITIAL_LINKS) multiplied by the amount of nodes in the map (m_cNodes)" rules (the "level designer don't trust links to be made" paranoia). Instead of returning true, false will be returned but before returning said result, the index of the node that was being treated is stored in that &piBadNode parameter.Since the result from doing those initial links is
false, the test hull switches to its ShowBadNode thinking method. This method basically teleport the test hull to the node and spam some particle effects to show you the problematic location. The node graph generation process is canceled in that situation.Assuming we have no "bad nodes", we can go back to the initial
BuildNodeGraph() method. We have links but there is an important problem that need to be solved: "size". Remember that those links were checked with trace lines, monsters aren't lines, they are "boxes" (square or rectangular). A gargantua cannot possibly traverse ventilation shafts designed for headcrabs and crouched players. So these links need extra information to determine which monsters can and cannot pass.This is where the link's
m_afLinkInfo comes in which can have one or more of the following bits:
#define bits_LINK_SMALL_HULL (1 << 0) // headcrab box can fit through this connection
#define bits_LINK_HUMAN_HULL (1 << 1) // player box can fit through this connection
#define bits_LINK_LARGE_HULL (1 << 2) // big box can fit through this connection
#define bits_LINK_FLY_HULL (1 << 3) // a flying big box can fit through this connection
#define bits_LINK_DISABLED (1 << 4) // link is not valid when the set- First, assume that everyone and everything can traverse this link.
- Start with the smallest hull size, on the first iteration, this is the small hull (for monsters like headcrabs).
- The test hull entity resize itself to match the hull's size.
- It teleport itself at the source node.
- If testing a link of two water nodes, the entity give itself the
FL_SWIMflag (this is reset at the end of the iteration). - Look in the direction of the destination node.
- Tell the engine to simulate a walking step of 16 units (
#define HULL_STEP_SIZE 16) into that direction. - Repeat previous step unless the engine tells the simulation failed or the destination has been reached, a local variable called
bool fWalkFailedis used to keep track of that. - If
fWalkFailedisfalse, do a sanity check of the distance between the test hull entity and the destination node, if it's higher than 64 units, then it's a failure (bogus walk) andfWalkFailedbecomestrue. - If
fWalkFailedistrue, the assumption that this hull size can traverse the link is proved incorrect, the bit flag of the hull being tested as well as the larger ones are unset fromm_afLinkInfoand we move on straight to checking the next link. - Otherwise (
fWalkFailed == false), repeat the whole algorithm from the second step but with the next hull size which is larger than the previous one (on second iteration, this is the human sized one).
After all links have passed that test, a method called
int WorldGraph.RejectInlineLinks(CLink* pLinkPool, FSFile& file) is called. In a nutshell, it check for each link if there is another one for a different node "in-between".To explain this better: picture a triangle (a 2D triangle to be exact, not to be confused with a 3D pyramid) where each vertex is a node and has a name: A (bottom left), B (top) and C (bottom right). Each line connecting A-B, B-C and A-C is a link. If you need a drawing to help you, here's one:
Let's go back to the code, the method finishes by returning the amount of links it rejected. Worth mentioning that those rejected links are logged in the report file. Another thing worth mentioning about this method: it sets the link's weight (
m_flWeight) as the distance between the source node and the destination node being tested.Before proceeding further, remember that we used a temporary list of links. Furthermore,
int WorldGraph.RejectInlineLinks(CLink* pLinkPool, FSFile& file) likely removed some of these links. So we allocate the right amount of memory for the final list (WorldGraph.m_pLinkPool) and copy from the temporary to the final one.
A recap so far
So now you know how nodes and links are generated but also how the latter are optimized a bit. But before we keep studying the node graph, you might feel "lost", "confused" with all of these explanations and maybe the drawings weren't enough. In order to help digest all of this information, here's a recap of everything we've seen so far by looking at the process in action.Instead of using an existing map from Half-Life's campaign, we're going to use a community map called "Bridge The Gap 2.0" made by Urby (used with permission) which you can download and play after reading this page if you haven't already from the TWHL Vault. After installing the map, starting it and letting the node graph process generation complete with the "recording" of steps. We can finally look at the whole stuff. First, let's see how the "initial links" in two places of the maps are created. As a remainder, those "initial links" are created by tracing lines between two nodes and checking if they're not blocked.
Final steps
At this point, we could consider the node graph generation to be "complete" and we could just write the result to file and call it a day. However, there was a problem.Monsters could request information from the node graph at any time, could be the location of a node with a specific constraint (usually the one closest to the monster itself or target or cover), could be a path from two nodes with constraints (shortest one, avoid obstacles...) and so on.
With a low amount of nodes, links and simple map geometry complexity, this would maybe not be a big deal. However, the reversed situation could happen. You need to keep in mind that Half-Life was released back in 1998. In that time period, we didn't had those fancy 64 bits, multi-cores, GHz clock speeds of processors from 2024, we only had a few 16 bits, single core and a few hundred of MHz clock speed (a Pentium 2 was 333 MHz back then). The same holds true for the memory (RAM) where we only had 16/32 Mb SDRAM and not those 16/32 Gb DDR4/DDR5 of today.
Short version: back in 1998, optimization was not an optional thing, it was a mandatory requirement. So Valve had to use many tricks to optimize the code and make sure the game would run smoothly on the hardware of that period.
Because there is a lot to talk about those optimization techniques, this will be discussed in a future page. For now, we're going to skip looking inside
WorldGraph.SortNodes() and WorldGraph.BuildLinkLookups().We're also going to skip that next
for loop that iterates over the nodes and it's inner for loop for the links as this is "validation" of an optimization technique to be discussed in said future page.And we're skipping the call to the
WorldGraph.BuildRegionTables() method. We're finally back to the original subject. Most importantly:
- All land nodes are pushed to the ground (
m_vecOrigin.z -= NODE_HEIGHT). - The temporary list of link is freed from memory since we have the final one with the correct size.
- The report/log file (
.nrp) is closed. - The node graph is considered to be present (
m_fGraphPresent = true).
WorldGraph.FSaveGraph(const char* szMapName). This is a "standard write file function" which create the maps/graphs folder hierarchy if needed, create the <mapname>.nod file in it and write everything that has been generated previously in the same order as reading it (graph version, nodes, links...)Don't worry about
bool WorldGraph.m_fRoutingComplete and the WorldGraph.ComputeStaticRoutingTables() method, this is another optimization trick to be discussed at a later date.Speaking of reading, there is one more thing that happens when the node graph is being loaded. When the player is being precached (
CBasePlayer::Precache()), a call to WorldGraph.FSetGraphPointers() is made. This method iterates on the list of links, search if the entity's model name is set (FIND_ENTITY_BY_STRING on the model key/value) and assign the m_pLinkEnt pointer if found. It also set the FL_GRAPHED flag if needed. If the entity is not found, a warning is printed in the console. This also explains the purpose of bool WorldGraph.m_fGraphPointersSet.
- Categories
- Tutorials
- Programming
- Goldsource Tutorials
- Article Credits
-
 Shepard62FR
–
Original author
Shepard62FR
–
Original author
-
 monster_urby
–
Bridge The Gap 2.0
monster_urby
–
Bridge The Gap 2.0
Comments
You must log in to post a comment. You can login or register a new account.